Video
Abstract
Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions.
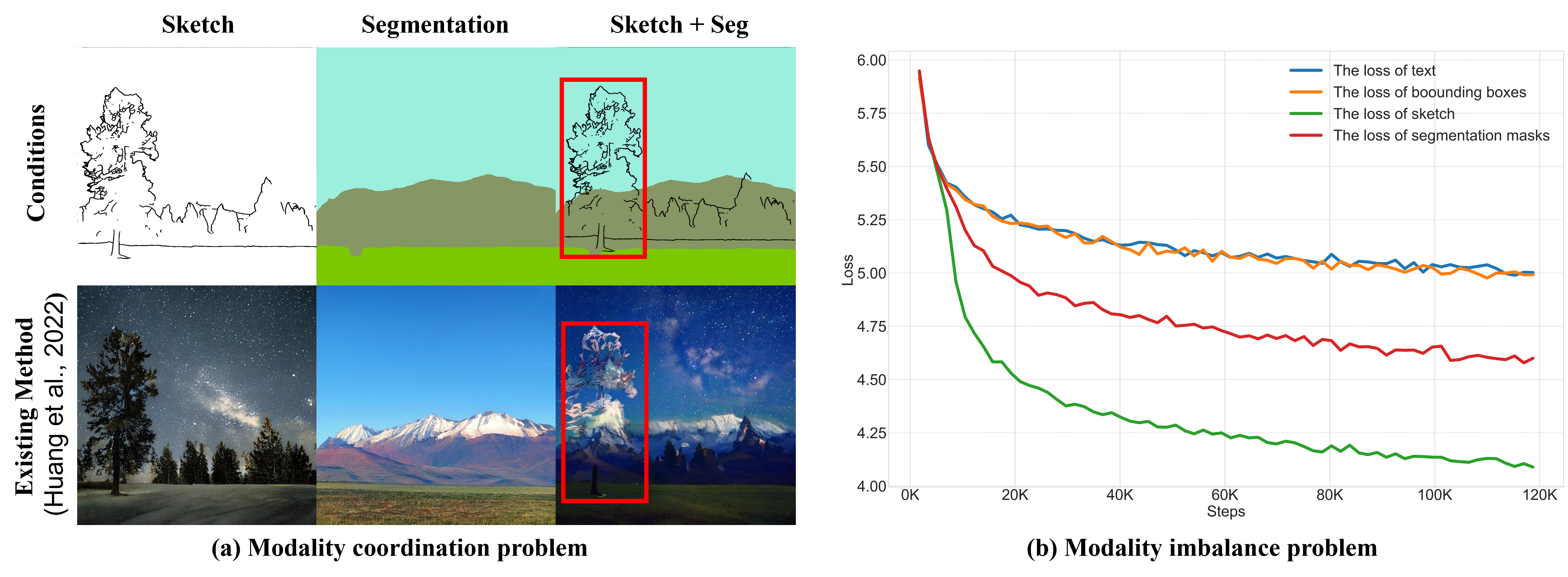
(a) Modality coordination problem in PoE-GAN: the tree incorrectly composed with the mountain. (b) Modality imbalance problem in PoE-GAN: the text input is simply ignored. In contrast, our approach can not only synthesize high-quality images when conditioned on a single modality but also generate reasonable results when conditioned on complex compositions of multimodal inputs.
Framework
The figure below is the overview of the Mixture-of-Modality-Tokens Transformer for CMCIS task. Given image and multiple modalities, including text, segmentation masks, sketch and bounding boxes, we tokenize them into discrete tokens with different tokenizers, and then (a) model intra-modal interaction with modality-specific encoders; (b) inject multimodal conditioning information into the decoder with modality-specific cross-attention; (c) adaptively fuse conditional signals via the multistage token-mixer. We train MMoT with multimodal balanced loss and sample with divergence-driven multimodal guidance.
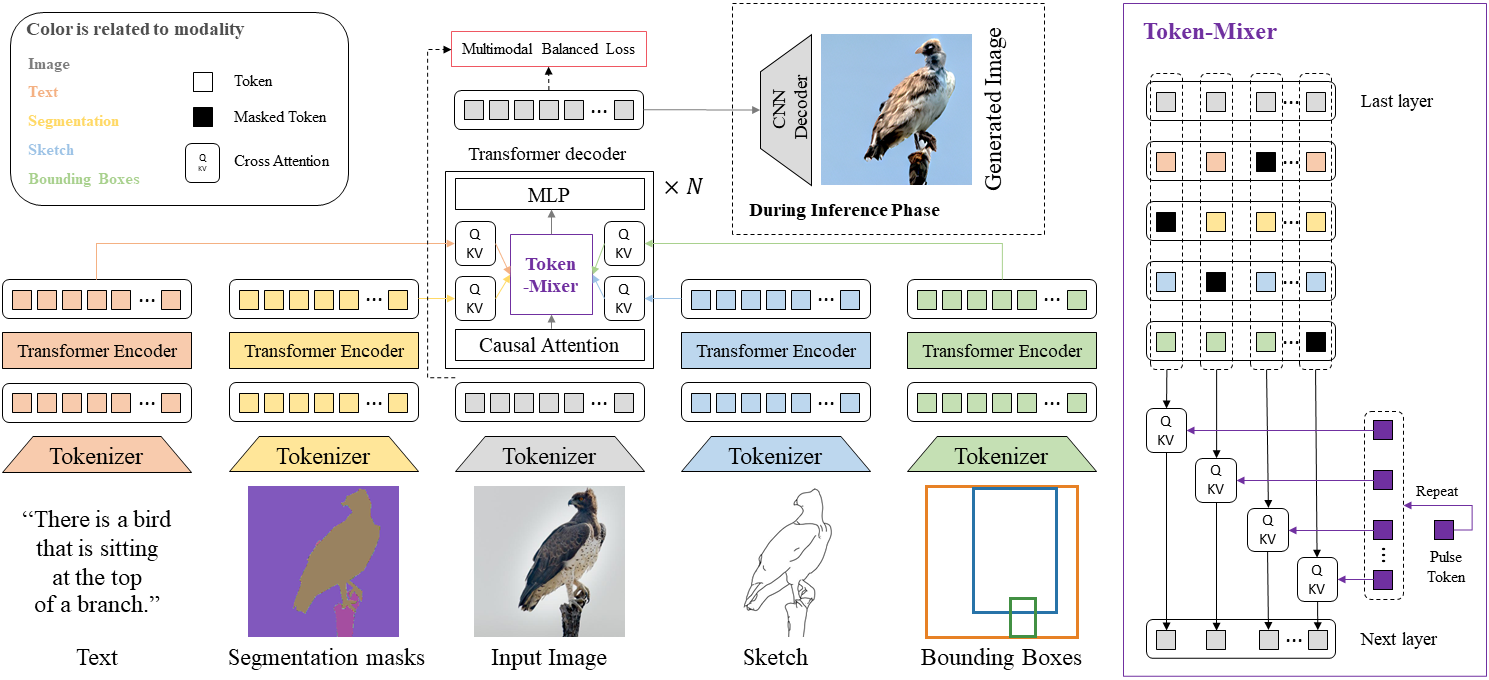
Our framework. Check our paper to see more details of the framework.
Results
MMoT achieves superior performance on UCIS task compared with a wide range of existing methods, including text-to-image methods (DF-GAN, DM-GAN+CL), segmentation-to-image methods (SPADE, OASIS) sketch-to-image methods (Pix2PixHD, SPADE, VQGAN+T) layout-to-image methods (LostGAN-V2, Context-L2I, TwFA) and the state-of-the-art MCIS method (PoE-GAN).
A view of mountains from the window of a jet airplane.




A blueberry cake is on a plate and is topped with butter.




A red blue and yellow train and some people on a platform.




A man blowing out candles on a birthday cake.



A desk set up as a workstation with a laptop.




Qualitative comparison of text-to-image synthesis on COCO-Stuff.









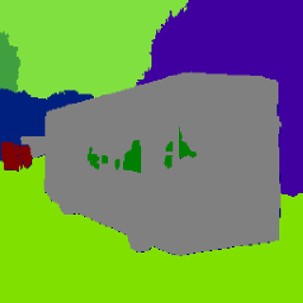









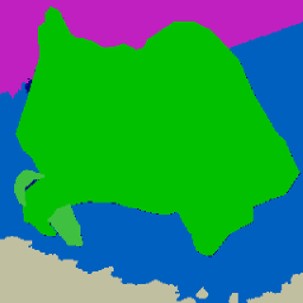




Qualitative comparison of segmentation-to-image synthesis on COCO-Stuff.
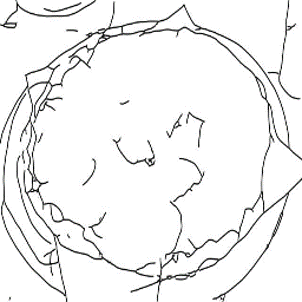

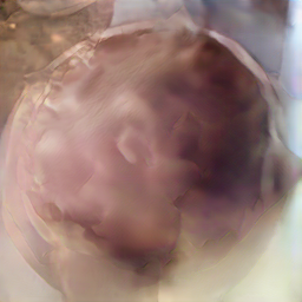


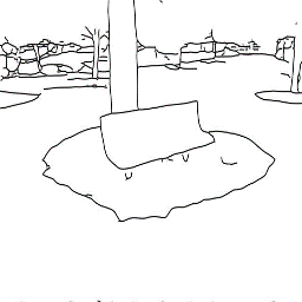


















Qualitative comparison of sketch-to-image synthesis on COCO-Stuff.





















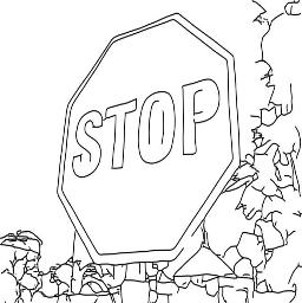
Qualitative comparison of layout-to-image synthesis on COCO-Stuff.
MMoT can generate high-quality, faithful, and diverse images when conditioned on complex compositions of different modalities while the MCIS model (PoE-GAN) is struggle with the modality coordination problem and the modality imbalance problem. Below we show some examples generated by PoE-GAN and our MMoT when tested on the CMCIS setting.
The mountain near the grassland.




A tree in the desert with mountains at a distance.




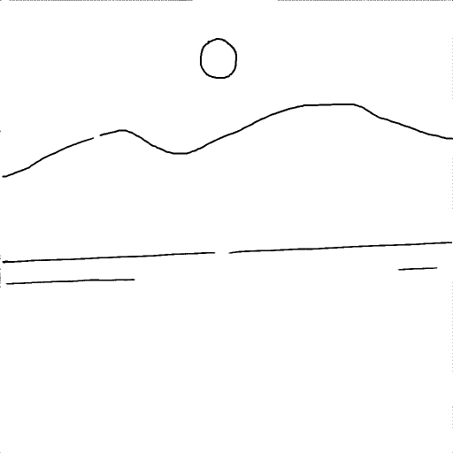
A beach with white sand, and the rising sun in the sky.




A waterfall between mountains.




A river in the desert.




The towering trees are surrounded by colorful clouds.




CMCIS samples conditioned on text+segmentation.
A tree stands in the desert.
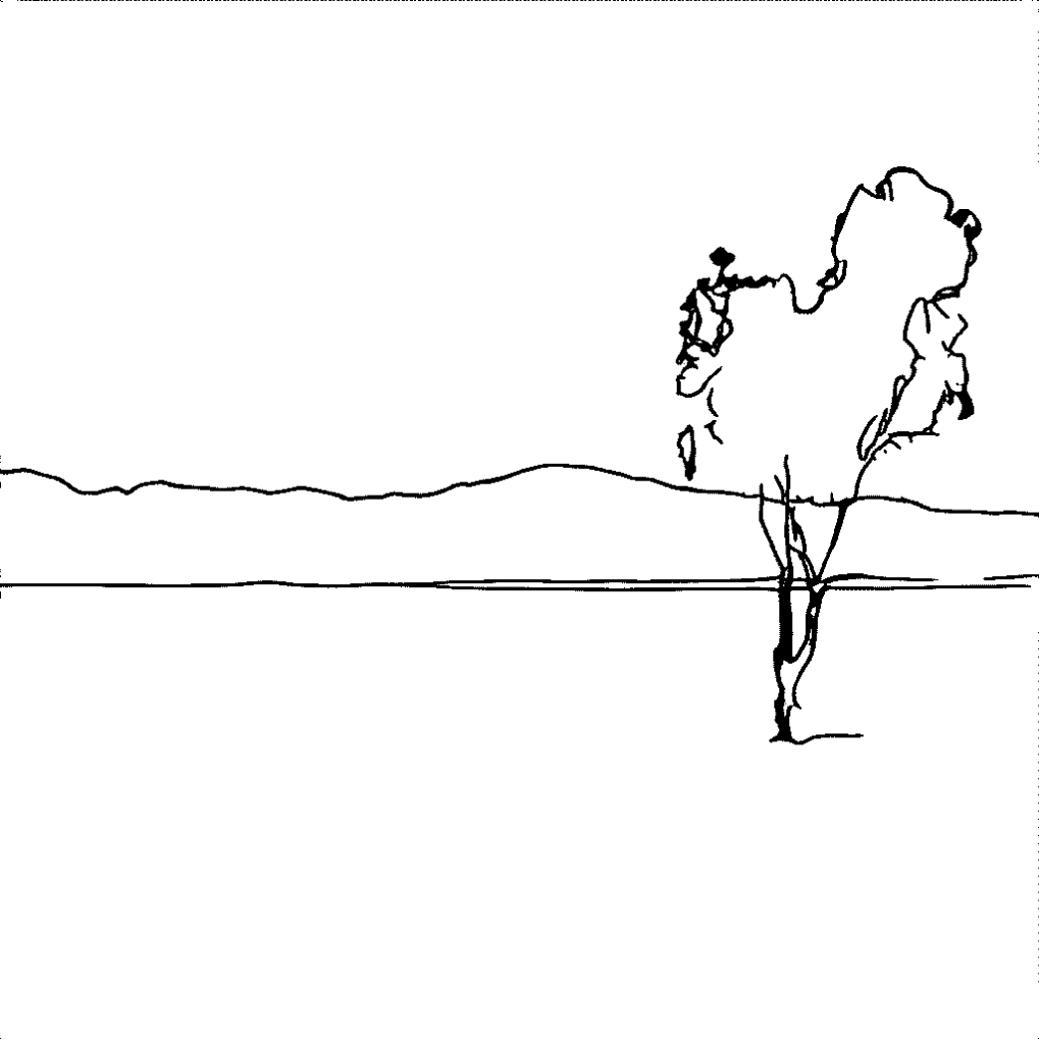



A tree stands on the river.
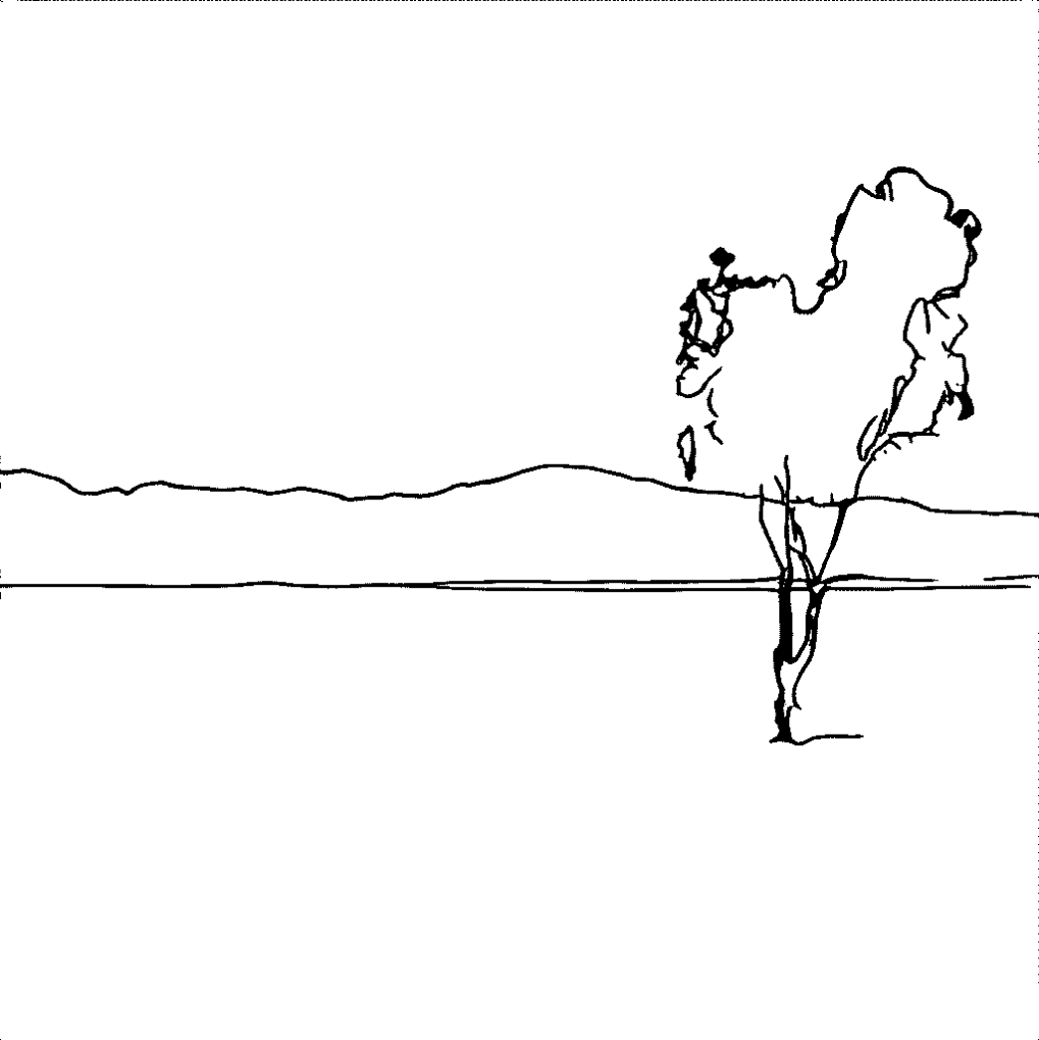



A small dirt road runs through the forest.
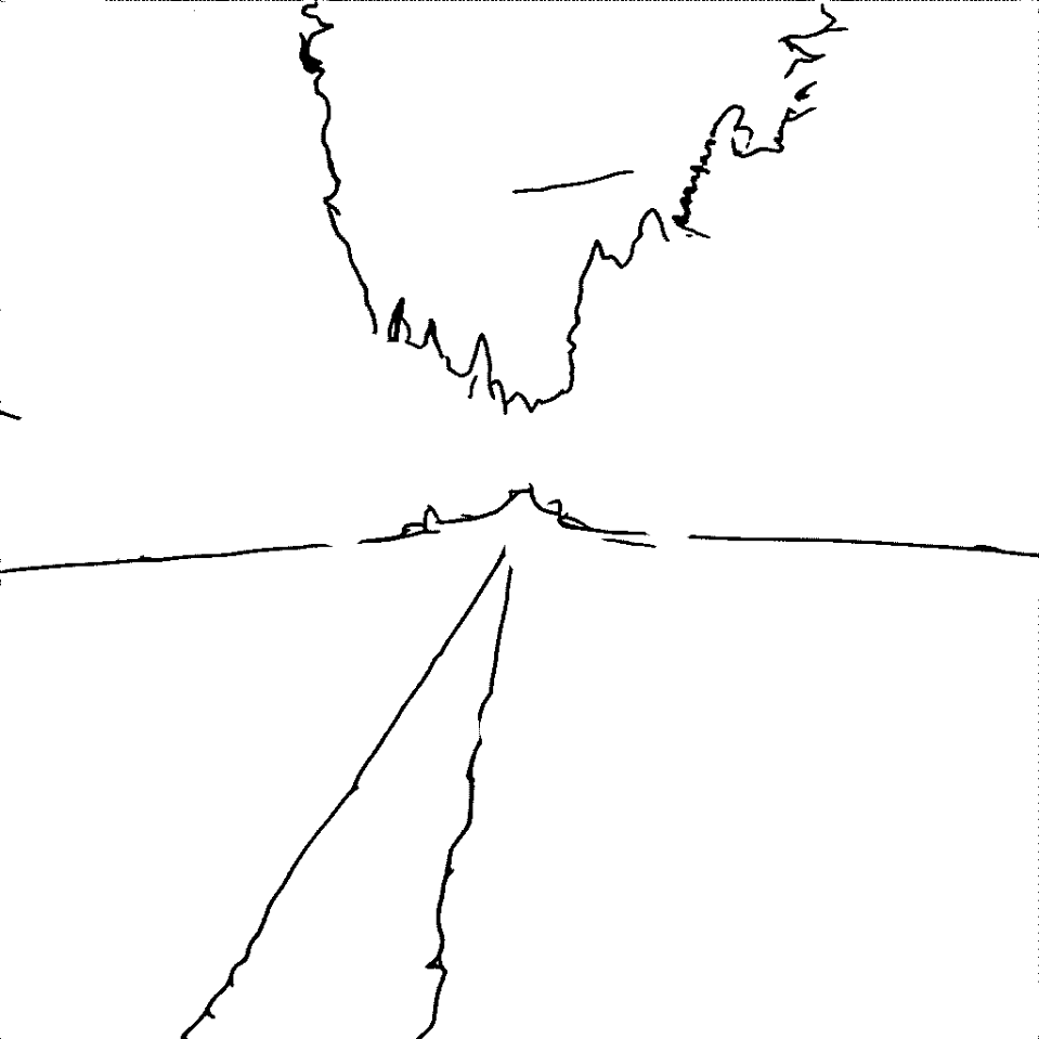



A lake in the gravel land with white clouds in the blue sky.




The rising sun in the sky.



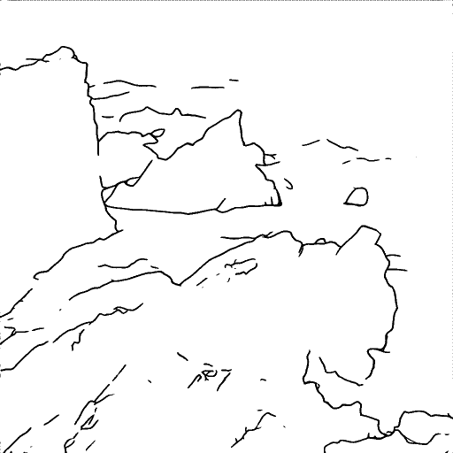
Ocean waves crash into rocks.



CMCIS samples conditioned on text+sketch.



















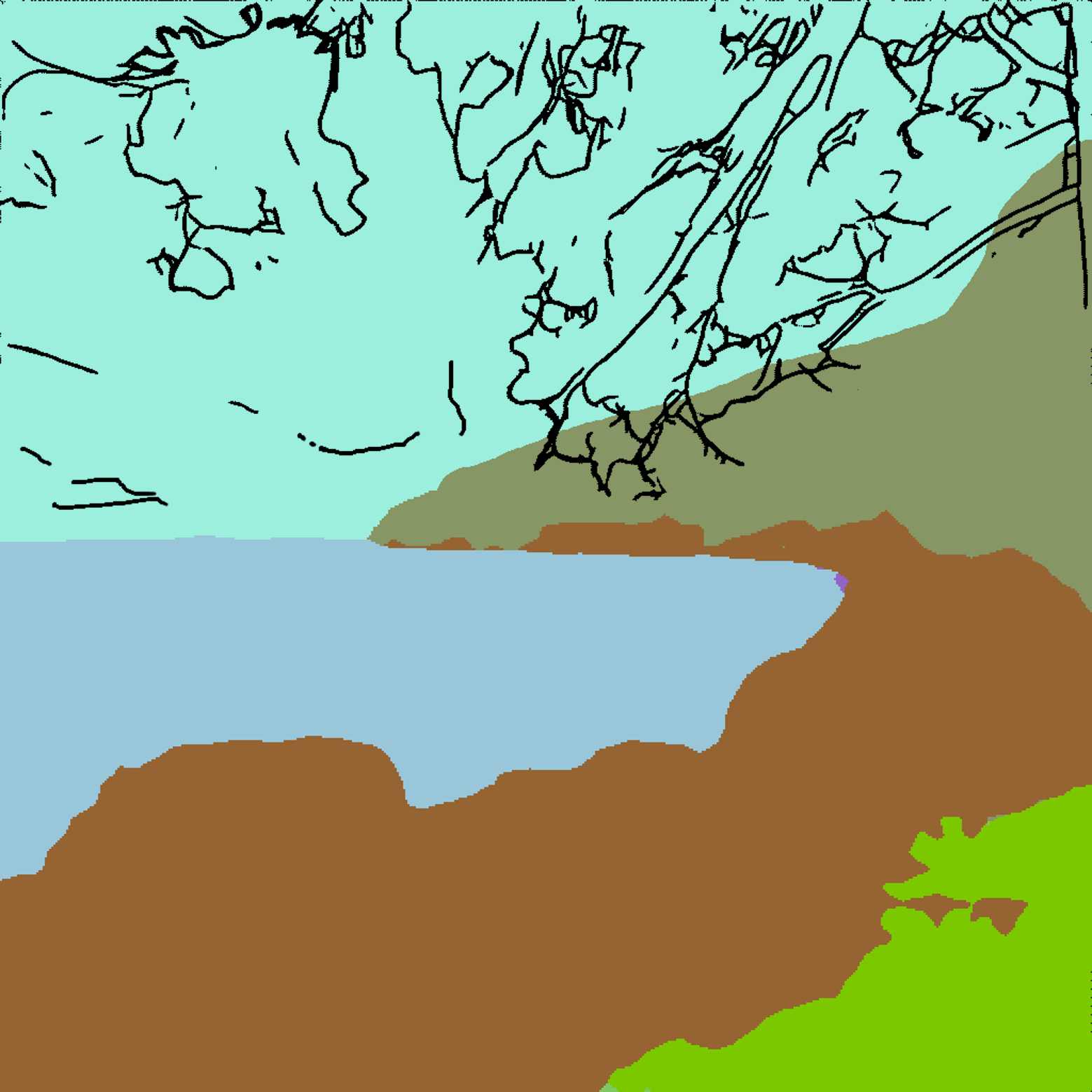









CMCIS samples conditioned on segmentation+sketch.
Below are examples of composed multimodal conditional image synthesis tested on CoCo-Stuff. We show three random samples from MMoT conditioned on compositions of different modalities (text+segmentation, text+sketch, text+layout, segmentation+sektch, layout+sketch).
Condition #1
(Text)
Condition #2
(Segmentation)
MMoT (Ours) #1
MMoT (Ours) #2
MMoT (Ours) #3
A small airplane is flying in the sky.




A kitchen and dining area decorated in white.




CMCIS samples conditioned on text+segmentation.
Condition #1
(Text)
Condition #2
(Sketch)
MMoT (Ours) #1
MMoT (Ours) #2
MMoT (Ours) #3
A passenger bus pulling up to the side of a street.
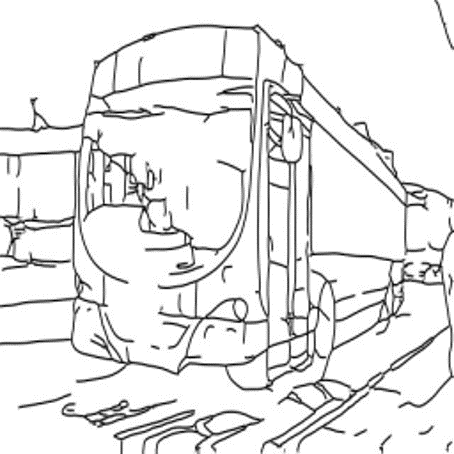



A dog following a man on his horse in a field.
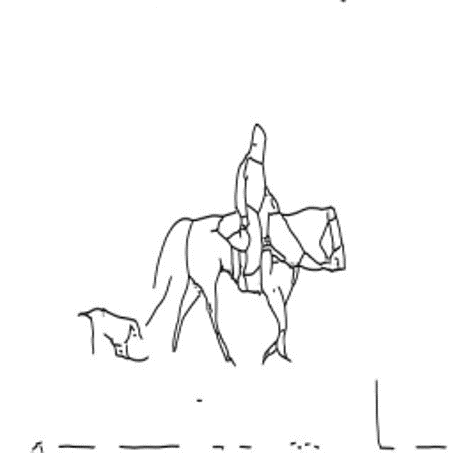



CMCIS samples conditioned on text+sketch.
Condition #1
(Text)
Condition #2
(Layout)
MMoT (Ours) #1
MMoT (Ours) #2
MMoT (Ours) #3
An urban intersection with stoplights on a cloudy day.



A white boat some green hills and water.
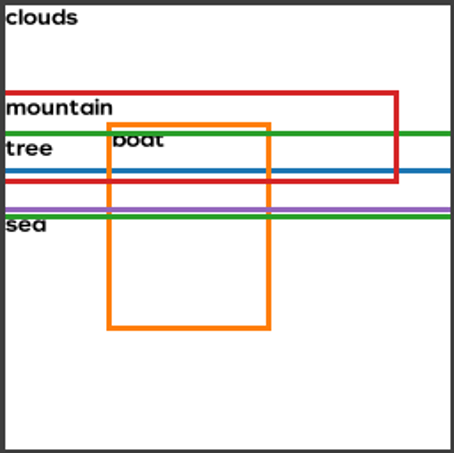



CMCIS samples conditioned on text+layout.
Conditions
(Segmentation+Sketch)
MMoT (Ours) #1
MMoT (Ours) #2
MMoT (Ours) #3
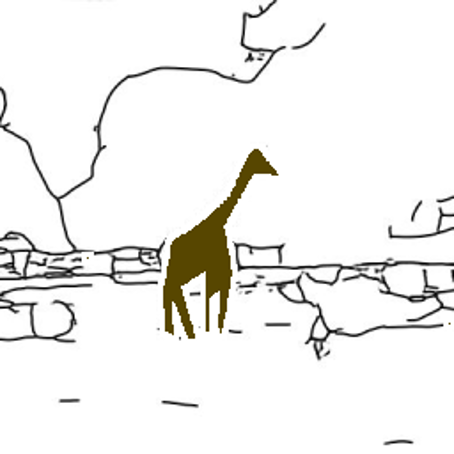







CMCIS samples conditioned on segmentation+sketch.
Conditions
(Layout+Sketch)
MMoT (Ours) #1
MMoT (Ours) #2
MMoT (Ours) #3
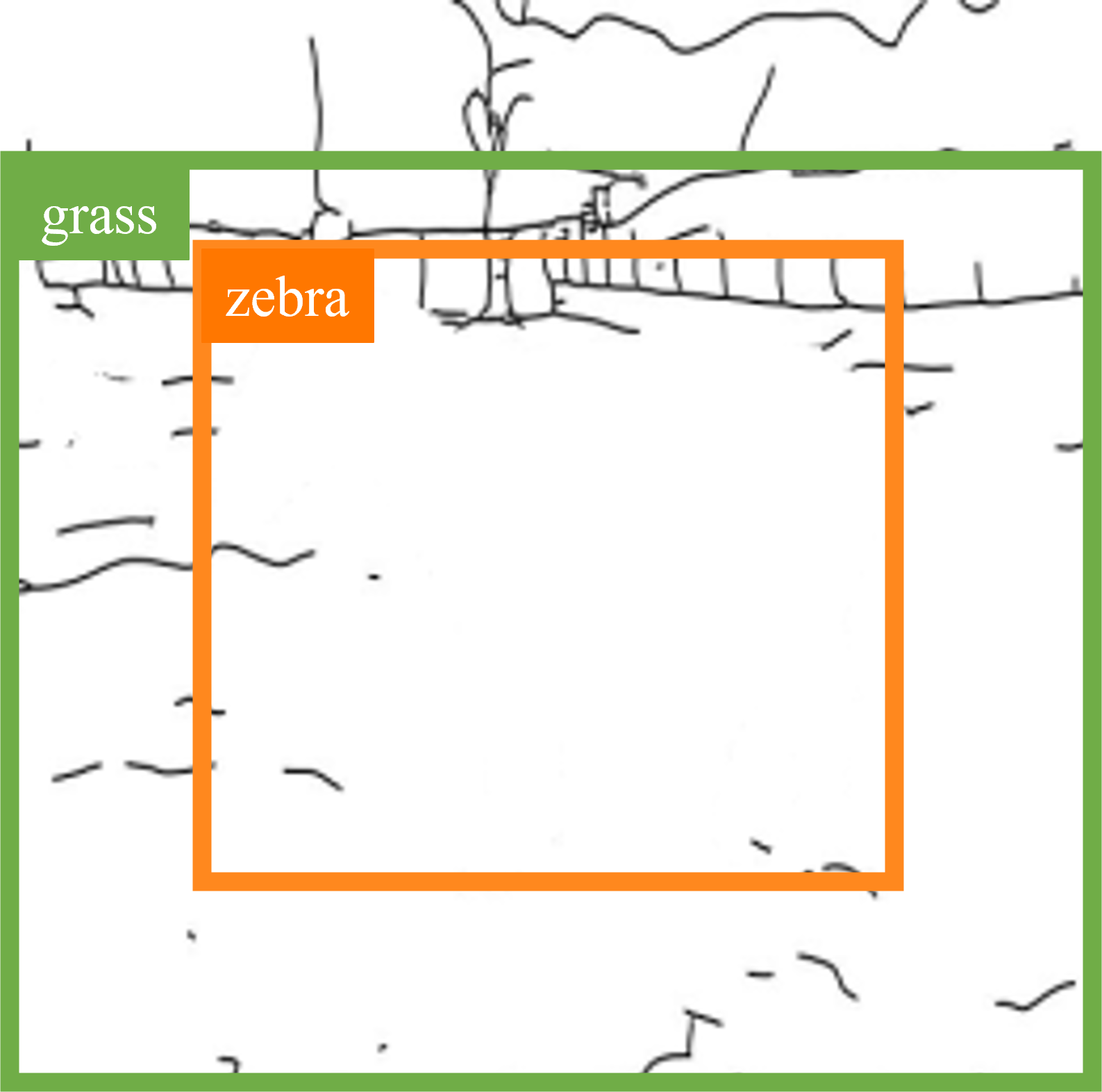



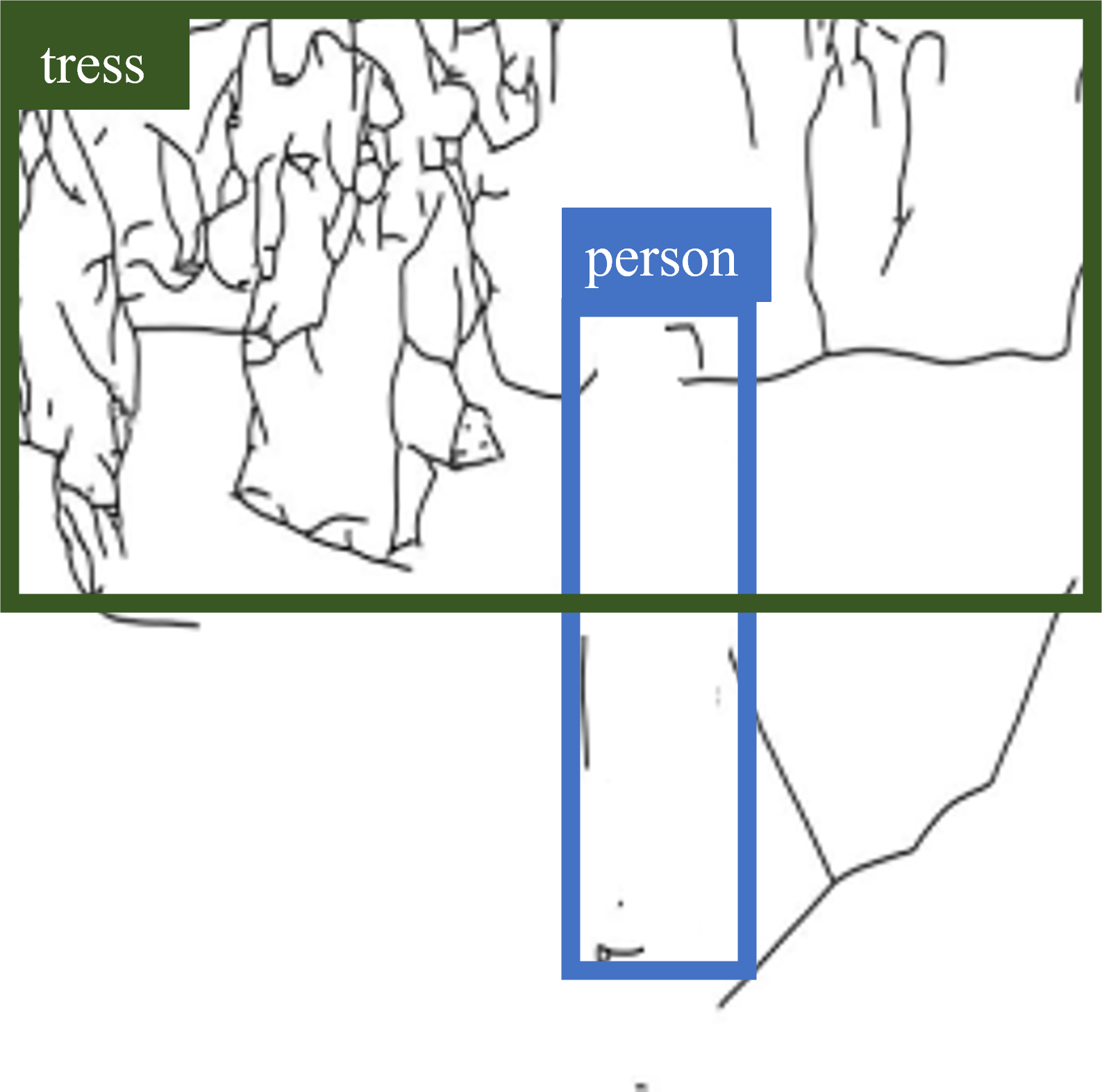



CMCIS samples conditioned on layout+sketch.
Citation
@article{zheng2023mmot,
title={MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis},
author={Zheng, Jianbin and Liu, Daqing and Wang, Chaoyue and Hu, Minghui and Yang, Zuopeng and Ding, Changxing and Tao, Dacheng},
journal = {arXiv},
year = {2023},
}
Acknowledgements
The website template was borrowed from PoE-GAN.